I was tasked to update our existing implementation that uses Auto Increment ID from MySQL as the ID for the public API. The objective of this task is to prevent enumeration attacks1 and ensure that the development effort is kept to a minimum.
The first thing that came to mind was to use a unique random ID like UUIDv42. However, since we are using MySQL as the database, indexing UUIDs has a significant performance impact3 due to their randomness and the locality problem of the B-Tree Index4.
Another option is to use ULID5, but it’s not natively supported by MySQL, or UUIDv7, which is still in draft6. The Twitter Snowflake ID7 is also a good option, but it’s predictable since it exposes the timestamp and also requires a dedicated server to generate the ID, which is lead to increase the development effort.
Thankfully, I had previously written my own implementation of UUID and MongoDB ObjectID8 from scratch for fun and learning. This experience gave me a mental model of how unique IDs are designed. With the help of my Computer Science background, I realized that I can use Steganography to hide the Auto Increment ID within a random string, in this case, the UUIDv4, and still be able to retrieve the Auto Increment ID if we know the algorithm and the secret number used to generate a new ID.
This reversibility is essential for utilizing the auto-increment ID for database queries and the UUID as a security token. A security token is essentially like a signature that can be used to verify if the auto-increment ID is indeed the correct pair of the UUIDv4.
Instead of changing the way the ID is stored, I decided to change the perspective to change the way the ID is exposed. That’s the problem we want to solve!
My objective is to create an ID that is only used for the public API, which contains the Auto Increment ID but is very hard to guess if we don’t know how the ID is generated. That’s why I call this technique ShadowID, because it’s not the real ID that we store in the database, but it’s a shadow of the real ID.
By using this approach, the only change in the database schema is to add a new column to store the UUIDv4 without indexing it, which is very easy to do using a migration script to generate the UUIDv4 for all existing records. The rest of the implementation is just a simple algorithm to generate the ShadowID from the Auto Increment ID and the UUIDv4.
We use Go, and fortunately, we separate the types used by the Schema (which we call “Entity”) and the types for the API (which we call “DTO”).
So we can create a new type for the ShadowID and use it for the API. The ShadowID then implements the json.Marshaler
and json.Unmarshaler interfaces to automatically handle the serialization and deserialization of the ShadowID to and
from JSON.
The only remaining problem is how to generate the ShadowID from the Auto Increment ID and the UUIDv4. Let’s take a look at the code below:
// defaultSalt is the default salt used to conceal the autoincr and random ID (UUIDv4).
// This acts as a private key.
var defaultSalt atomic.Uint64
// SetSalt sets the default salt.
func SetSalt(s uint64) { defaultSalt.Store(s) }
// ShadowID is a 24-byte ID that conceals the autoincr and random ID (UUIDv4).
// 24 bytes = 8 bytes of autoincr + 16 bytes of UUIDv4
type ShadowID [24]byte
// NewShadowID generates a new ShadowID from the given autoincr and random ID (UUIDv4).
func NewShadowID(autoincr int64, randomid uuid.UUID) ShadowID {
var id ShadowID
// NOTE 1: Take 8 bytes from the random ID as the random salt. We can take any 8 bytes from the random ID,
// but for this case, we take the last 8 bytes.
// NOTE 2: We take 8 bytes since the defaultSalt and autoincr are 8 bytes.
randomSalt := binary.LittleEndian.Uint64(randomid[8:16])
// NOTE 3: Generate the salted ID by XOR-ing the autoincr, random salt, and default salt.
// NOTE 4: We XOR because we want to ensure that this ID is reversible.
salted := uint64(autoincr) ^ randomSalt ^ defaultSalt.Load()
// NOTE 5: Put the 8 bytes of the UUID's LSB into the first 8 bytes of the ShadowID.
copy(id[:8], randomid[:8])
// NOTE 6: Put the 4 bytes of the salted ID's LSB into the 8th-12th byte of the ShadowID.
// NOTE 7: We use BigEndian because we want to ensure that the byte order matches the hex encoded salted ID.
// For example, if the salted ID in hex is c82e0b54_0495ed56, the id[8:12] will be 0495ed56, and the
// id[12:20] will be c82e0b54.
binary.BigEndian.PutUint32(id[8:12], uint32(salted))
// Same as before, the only difference is the offset.
copy(id[12:20], randomid[8:16])
// NOTE 8: We need to shift half of the bits to the right to move the MSB to the LSB.
// Converting by uint32 will only take 4 bytes from the LSB.
binary.BigEndian.PutUint32(id[20:], uint32(salted>>32))
return id
}
The salted is computed by applying XOR to the autoincr, randomSalt, and defaultSalt. The defaultSalt is our
secret key that must be defined in the environment variable. If not set, the default value is 0. It is important to note
that the salted must be unique for any given autoincr and randomSalt pair. If you are interested in learning how
to prove this, please refer to my article titled “*
*A Simple Proof of XOR Uniqueness**.”
BigEndian and LittleEndian9 are just the ways we interpret binary data. For example, if we have a 32-bit integer
with the value 0x12345678, BigEndian will interpret it as 0x12 0x34 0x56 0x78, while LittleEndian will interpret
it as 0x78 0x56 0x34 0x12.
Too much binary manipulation, right? Let’s take a look at the diagram below to better understand the algorithm:
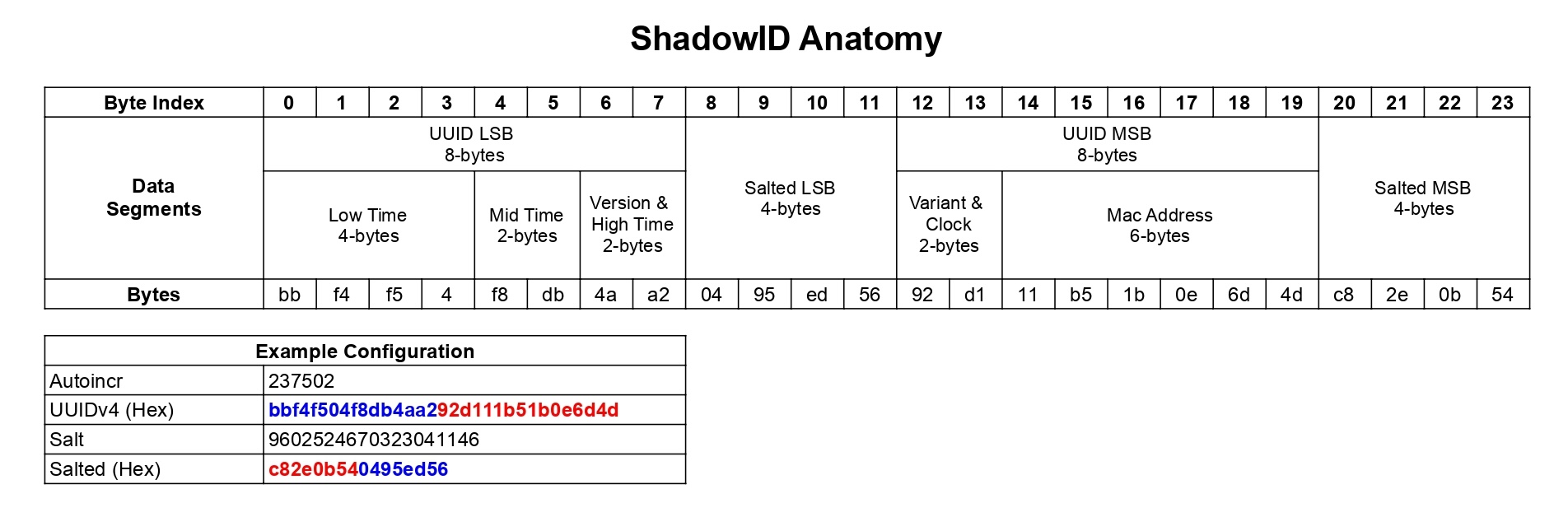
You can find the UUIDv4 anatomy in this article. The naming that I used in the diagram is based on the UUIDv1 anatomy, the only difference with UUIDv4 is in the UUIDv4 all the bytes are random.
The NewShadowID function converts the salted and the randomid into binary form and places them into
the ShadowID, following the structure shown in the diagram above. In the diagram, the blue color represents the LSB,
while the red color represents the MSB. I recommend that you revisit the code and the notes while referring to the
diagram to gain a better understanding of the algorithm.
Essentially, we have already successfully concealed the autoincr and randomid within the ShadowID. Let’s proceed
with implementing the serialization and deserialization of the ShadowID to and from JSON:
// String returns the string representation of the ShadowID.
func (id ShadowID) String() string {
text, _ := id.MarshalText()
return string(text)
}
// MarshalText implements the encoding.TextMarshaler interface, this also covers json.Marshal.
func (id ShadowID) MarshalText() ([]byte, error) {
enc := make([]byte, hex.EncodedLen(len(id)))
hex.Encode(enc, id[:])
return enc, nil
}
// UnmarshalText implements the encoding.TextUnmarshaler interface, this also covers json.Unmarshal.
func (id *ShadowID) UnmarshalText(text []byte) error {
if len(text) != hex.EncodedLen(len(id)) {
return fmt.Errorf("shadowid: unmarshal text: invalid length %d", len(text))
}
_, err := hex.Decode(id[:], text)
if err != nil {
return fmt.Errorf("shadowid: unmarshal text: %w", err)
}
return nil
}
Those functions are quite straightforward. We utilize the encoding/hex package to convert the ShadowID to and from a hexadecimal string. The ShadowID is represented as a hexadecimal string in JSON. The MarshalText and UnmarshalText functions are also employed by the encoding/json package for the purpose of serializing and deserializing the ShadowID to and from JSON.
Let’s observe this in action:
func main() {
shadowid.SetSalt(9602524670323041146)
autoincr := int64(237502)
randomid, _ := uuid.Parse("bbf4f504f8db4aa292d111b51b0e6d4d")
id := shadowid.NewShadowID(autoincr, randomid)
fmt.Println(id)
}
We used the same values for autoincr and randomid as the example in the diagram above. The output is:
bbf4f504f8db4aa292d111b51b0e6d4d0a0e0b54
As we can see, it matches the diagram above. Now, let’s attempt to reverse the process by extracting the autoincr and randomid from the ShadowID. Let’s create a new function to accomplish this:
func main() {
shadowid.SetSalt(9602524670323041146)
const raw = `{"id":"bbf4f504f8db4aa20495ed5692d111b51b0e6d4dc82e0b54"}`
var target struct {
ID shadowid.ShadowID `json:"id"`
}
if err := json.Unmarshal([]byte(raw), &target); err != nil {
panic(err)
}
fmt.Println(target.ID)
}
The output remains the same as in the previous example. Let’s create a new function to directly extract autoincr and randomid from the ShadowID:
// RandomID returns the random ID (UUIDv4) from the ShadowID.
func (id ShadowID) RandomID() uuid.UUID {
var uid uuid.UUID
// Based on the ShadowID anatomy, the random ID consists of the first 8 bytes and the 12th-20th bytes.
// So, let's copy the first 8 bytes and the 12th-20th bytes to the UUID.
copy(uid[:8], id[0:8])
copy(uid[8:], id[12:20])
return uid
}
// Autoincr returns the autoincr from the ShadowID.
func (id ShadowID) Autoincr() int64 {
var autoincr [8]byte
// This is a bit tricky: in NewShadowID, we placed the salted ID's LSB into the 8th-12th and 20th-24th bytes.
// Since we used BigEndian for both, we need to reverse the order of the salted ID's LSB.
copy(autoincr[:4], id[20:])
copy(autoincr[4:], id[8:12])
// Converts the salted ID to uint64
salted := binary.BigEndian.Uint64(autoincr[:])
// We take the random salt from the UUID.
randomSalt := binary.LittleEndian.Uint64(id[12:20])
// Apply the same XOR operation as in NewShadowID.
return int64(salted ^ randomSalt ^ defaultSalt.Load())
}
The RandomID is very simple; we just need to take the first 8 bytes and the 12th-20th bytes from the ShadowID and place them into the uuid.UUID. However, the Autoincr is a bit tricky. We need to reverse the order of the LSB in the salted ID since we used BigEndian for both the ShadowID and the salted in NewShadowID. Afterward, we can convert the salted ID to a uint64 and apply the same XOR operation as in NewShadowID.
Let’s see this in action:
func main() {
shadowid.SetSalt(9602524670323041146)
const raw = `{"id":"bbf4f504f8db4aa20495ed5692d111b51b0e6d4dc82e0b54"}`
var target struct {
ID shadowid.ShadowID `json:"id"`
}
if err := json.Unmarshal([]byte(raw), &target); err != nil {
panic(err)
}
fmt.Println("ShadowID:", target.ID)
fmt.Println("RandomID:", target.ID.RandomID())
fmt.Println("Autoincr:", target.ID.Autoincr())
}
The output will be:
ShadowID: bbf4f504f8db4aa20495ed5692d111b51b0e6d4dc82e0b54
RandomID: bbf4f504-f8db-4aa2-92d1-11b51b0e6d4d
Autoincr: 237502
As we can see, we have successfully reversed the process and obtained the autoincr and randomid from the ShadowID.
We have completed the implementation of the ShadowID. However, there is something unique about the bytes that have a length divisible by 3. If we convert these bytes to base64, the result will be a string with no padding. This is because base64 groups the bytes into sets of 3 and converts them into 4 characters.
By leveraging this property, we can reduce the length of the string representation of the ShadowID from 48 characters to 32 characters (4 * 24/3 = 32). For now, let’s keep it in hexadecimal.
Conclusion
We have successfully created a unique ID that conceals the Auto Increment ID and is very hard to guess if one does not know how the ID is generated. This is a great way to expose the Auto Increment ID to the public without compromising security.
This technique is not limited to this implementation. You can design your own algorithm or create your own Anatomy of the ShadowID to make it even more secure.
In my task, as I mentioned at the beginning of this article, a completely different algorithm and Anatomy of the ShadowID were used. However, the core idea remains the same: by keeping the algorithm, anatomy, and secret key in a secure place, we make it even more challenging to guess, ensuring that only you and your team should know how to reverse the process.
I believe that covers everything for now. I hope you have enjoyed this article. If you have any questions or suggestions, please don’t hesitate to leave a comment below. Thank you for reading!
You can find the code in this GitHub repository.